
{kind=link}
Évolution de C#
C’est Visual Studio 2012 qui permettra l’utilisation de la version à venir de C# 5.0 avec une CLR 4.5 mise à jour. C# est arrivé à un stade de maturité impressionnant mais est aussi très riche en termes de fonctionnalités disponibles. À chaque nouvelle version, il est remarquable de constater le travail effectué par l’équipe Visual C# de Microsoft qui ne cesse d’innover. Vous trouverez d’ailleurs dans le tableau ci-dessous les fonctionnalités clés de chaque version de C# :
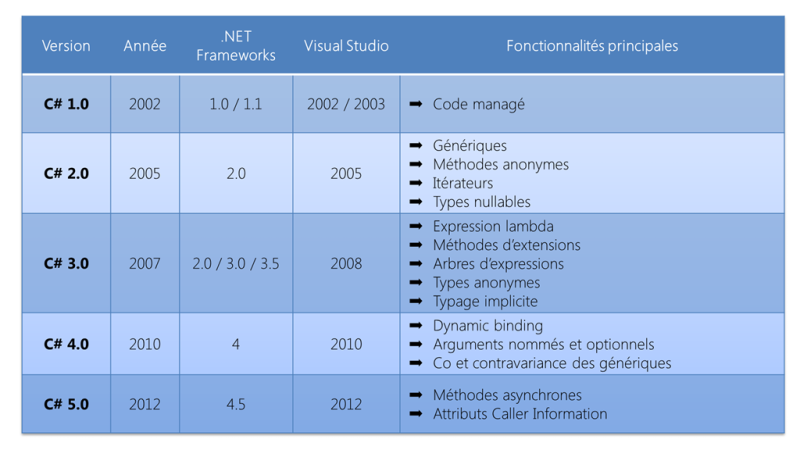
Comme vous pouvez le constater, deux fonctionnalités majeures sont présentes dans la nouvelle version de C# :
- Méthodes asynchrones ;
- Attributs Caller Information.
Sans attendre, nous allons tout de suite voir de quoi il est question.
Méthodes asynchrones
On peut vraiment dire que cette fonctionnalité est celle que tout le monde attendait dans cette nouvelle version de C#. L’enjeu de l’équipe Visual C# de Microsoft était de simplifier l’utilisation d’opérations asynchrones que nous sommes souvent amené à effectuer lorsque, par exemple, nous désirons éviter de figer une interface graphique pendant un traitement en arrière-plan prenant plus d’une demi-seconde. Jusqu’à présent, nous étions habitué à utiliser le mécanisme évènementiel de méthodes callback. Voici un exemple où il est question de récupérer le contenu d’une page web spécifiée par l’utilisateur.
public partial class MainWindow : Window
{
public MainWindow()
{
InitializeComponent();
}
private void buttonDownload_Click(object sender, RoutedEventArgs e)
{
var client = new WebClient();
client.DownloadStringCompleted += client_DownloadStringCompleted;
client.DownloadStringAsync(new Uri(textboxURL.Text), client);
}
void client_DownloadStringCompleted(object sender, DownloadStringCompletedEventArgs e)
{
if (e.Cancelled == false && e.Error == null)
{
textboxResult.Text = e.Result;
}
((WebClient)e.UserState).Dispose();
}
}En tant que développeur, on finit par s’habituer mais il faut avouer que ce pattern est lourd à mettre en place et compliqué à lire : il faut s’abonner à un évènement, créer une méthode callback, manipuler un EventArgs et enfin caster l’objet de départ afin d’effectuer un Dispose propre. De plus, nous sommes habitué à écrire du code séquentiel, c’est-à-dire un code qui s’exécute chaque ligne à la suite des précédentes. Dans l’exemple ci-dessus, on en est loin, la logique est divisée dans deux méthodes dont la seconde n’inspire aucune confiance : est-ce un appel suite à un évènement déclenché ou bien un développeur ayant désiré faire un appel direct à cette méthode ? Mais heureusement pour nous, C# évolue sans cesse afin de simplifier nos développements ou comment faire plus avec moins. Voici le même code mais cette fois écrit en C# 5.0 :
public partial class MainWindow : Window
{
public MainWindow()
{
InitializeComponent();
}
private async void buttonDownload_Click(object sender, RoutedEventArgs e)
{
var client = new WebClient();
var result = await client.DownloadStringTaskAsync(new Uri(textboxURL.Text));
textboxResult.Text = result;
}
}Comme vous pouvez le remarquer, C# 5.0 introduit deux nouveaux mots clés : async et await. Ces nouveaux mots clés vont permettre d’écrire du code asynchrone basé sur les classes Task et Task<TResult> du .NET Framework 4.0.
Le mot clé async indique que notre méthode est asynchrone. Grâce à cela, nous allons pouvoir identifier plus facilement les méthodes qui pourraient être longues en termes d’exécution et donc qu’il serait préférable d’utiliser de manière asynchrone.
L’utilisation du mot clé async dans une méthode suppose que le mot clé await est utilisé au moins une fois dans son implémentation (si ce n’était pas le cas, vous obtiendriez un Warning). Ce mot clé est appliqué sur une tâche (Task ou Task<TResult>) et permet de suspendre l’exécution d’une méthode asynchrone jusqu’à la fin de l’exécution de cette tâche.
La méthode marquée comme asynchrone va donc s’exécuter de manière synchrone au départ. Ce n’est que quand la méthode voudra exécuter une ligne avec une tâche évaluée par await que l’exécution sera suspendue pour lancer une exécution asynchrone de la tâche. Ainsi, le thread principal de l’interface récupère la main pendant cette exécution asynchrone. Une fois que cette tâche est terminée, l’exécution revient sur la ligne marquée await afin de récupérer le résultat de l’opération asynchrone. L’exécution synchrone de la méthode reprend ensuite son cours.
On obtient donc une exécution séquentielle du code malgré les opérations asynchrones !
Il est aussi intéressant de noter qu’une convention de nommage est fortement suggérée par Microsoft et qui est de suffixer une méthode asynchrone par « Async » afin que vous puissiez identifier de suite si la méthode que vous voulez utiliser est asynchrone ou non.
Il est important aussi de préciser que le mot clé async peut aussi être utilisé avec les méthodes anonymes et les expressions lambda.
Voici « buttonDownload_Click » réécrite avec une utilisation « traditionnelle » via une méthode anonyme :
private async void buttonDownload_Click(object sender, RoutedEventArgs e)
{
var client = new WebClient();
Func<Task> delegateToDownloadAsString = async delegate()
{
var result = await client.DownloadStringTaskAsync(new Uri(textboxURL.Text));
textboxResult.Text = result;
};
await delegateToDownloadAsString();
}Ou encore la même méthode avec l’utilisation d’une expression lambda :
private async void buttonDownload_Click(object sender, RoutedEventArgs e)
{
var client = new WebClient();
Func<Task> lambdaToDownloadAsString = async () =>
{
var result = await client.DownloadStringTaskAsync(new Uri(textboxURL.Text));
textboxResult.Text = result;
};
await lambdaToDownloadAsString();
}En résumé, si vous voulez utiliser await dans une méthode, cette méthode doit être marquée avec async et si vous désirez utiliser await au retour d’une méthode, cette méthode doit renvoyer une Task ou Task<TResult>.
Attributs Caller Information
Derrière cette nouvelle fonctionnalité se cache en fait trois attributs que vous allez pouvoir utiliser sur les arguments de vos méthodes afin d’obtenir des renseignements sur l’élément appelant. Il est possible de récupérer le nom du fichier code source qui a appelé la méthode, le numéro de la ligne dans ce fichier code source mais aussi le nom de l’élément appelant. Il va ainsi être très facile de développer des solutions de logs et de diagnostiques ! Voyez par vous-même comment il est possible d’utiliser cette fonctionnalité :
class Program
{
static void Main(string[] args)
{
try
{
int i = int.Parse("test");
}
catch (Exception exc)
{
new LogManager().LogException(exc);
}
}
}
public class LogManager
{
public void LogException(Exception exc,
[CallerMemberName] string memberName = "",
[CallerFilePath] string sourceFilePath = "",
[CallerLineNumber] int sourceLineNumber = 0)
{
Trace.WriteLine(string.Format("Date: {0}", DateTime.Now));
Trace.WriteLine(string.Format("Exception: {0}", exc.Message));
Trace.WriteLine(string.Format("Occured in: {0}", memberName));
Trace.WriteLine(string.Format("source file path: {0}", sourceFilePath));
Trace.WriteLine(string.Format("source line number: {0}", sourceLineNumber));
}
}L’attribut CallerMemberName permet de récupérer le nom du membre ayant appelé la méthode LogException. J’entends par « élément » une méthode, une propriété, un constructeur ou encore un destructeur. Les attributs CallerFilePath et CallerLineNumber permettent respectivement de récupérer le nom du fichier code source d’où provient l’appel et le numéro de la ligne dans ce même fichier d’où provient l’appel. Comme vous avez pu le remarquer, les attributs doivent être utilisés sur des arguments optionnels, sans cela, vous obtiendrez une erreur à la compilation. Si aucune valeur n’a été donnée explicitement, elle sera remplacée par la valeur déterminée grâce à l’attribut. Ce mécanisme n’est d’ailleurs pas impacté par l’offuscation du code car les valeurs des arguments sont écrites en dur dans le code IL lors de la compilation.
Scénario INotifyPropertyChanged
Comme je l’ai dit précédemment, ce mécanisme va s’avérer extrêmement puissant dans des scénarios de logs mais il s’avère aussi très utile dans un scénario récurrent que chacun d’entre vous a déjà dû rencontrer : l’utilisation de l’interface INotifyPropertyChanged. Vous avez sûrement déjà vu ce genre de code :
public class Customer : INotifyPropertyChanged
{
private int _ID;
private string _Name;
public event PropertyChangedEventHandler PropertyChanged;
public int ID
{
get { return _ID; }
set
{
if (value != this._ID)
{
this._ID = value;
NotifyPropertyChanged("ID");
}
}
}
public string Name
{
get { return _Name; }
set
{
if (value != this._Name)
{
this._Name = value;
NotifyPropertyChanged("Name");
}
}
}
private void NotifyPropertyChanged(string propertyName)
{
if (PropertyChanged != null)
{
PropertyChanged(this, new PropertyChangedEventArgs(propertyName));
}
}
}Le problème survient lorsqu’un jour on désire changer le nom d’une propriété… Si on oublie de renommer le paramètre écrit en dur à l’appel de la méthode NotifyPropertyChanged, on risque le bug qui n’apparaîtra que devant le client. C’est là que l’attribut CallerMemberName va nous être d’une grande utilité afin d’anticiper tout changement des noms de propriétés à venir. Nous n’avons plus besoin de passer d’argument à la méthode NotifyPropertyChanged. Il suffit simplement d’ajouter l’attribut en question sur l’argument propertyName et le rendre optionnel. Le code devient donc :
public class Customer : INotifyPropertyChanged
{
private int _ID;
private string _Name;
public event PropertyChangedEventHandler PropertyChanged;
public int ID
{
get { return _ID; }
set
{
if (value != this._ID)
{
this._ID = value;
NotifyPropertyChanged();
}
}
}
public string Name
{
get { return _Name; }
set
{
if (value != this._Name)
{
this._Name = value;
NotifyPropertyChanged();
}
}
}
private void NotifyPropertyChanged([CallerMemberName] string propertyName = null)
{
if (PropertyChanged != null)
{
PropertyChanged(this, new PropertyChangedEventArgs(propertyName));
}
}
}C’est donc à la compilation que les valeurs écrites en dur seront générées.
Utiliser les attributs avec les .NET Framework précédents
Ces nouveaux attributs sont disponibles uniquement avec la version 4.5 du .NET Framework, il semblerait donc logique de ne pas pouvoir les utiliser avec le .NET Framework 4. Il y a pourtant une astuce relayée sur le net et qui consiste à créer dans son code les trois attributs. Ainsi le compilateur Visual C# sous Visual Studio 2012 va avoir le même comportement qu’avec le .NET Framework 4.5.
namespace System.Runtime.CompilerServices
{
[AttributeUsage(AttributeTargets.Parameter, Inherited = false)]
public sealed class CallerMemberNameAttribute : Attribute
{
public CallerMemberNameAttribute();
}
[AttributeUsage(AttributeTargets.Parameter, Inherited = false)]
public sealed class CallerFilePathAttribute : Attribute
{
public CallerFilePathAttribute();
}
[AttributeUsage(AttributeTargets.Parameter, Inherited = false)]
public sealed class CallerLineNumberAttribute : Attribute
{
public CallerLineNumberAttribute();
}
}Vous pourrez ainsi utiliser cette fonctionnalité avec les .NET Framework 4, 3.5, 3.0 et 2.0 mais uniquement sous Visual Studio 2012 bien évidemment ! Notez aussi l’importance du namespace « System.Runtime.CompilerServices »qui est le même que celui dans le .NET Framework 4.5. Cette astuce s’explique par le simple fait que le compilateur vérifie uniquement que les trois types existent, peu importe la DLL où ils se trouvent.
Changement closure pour la boucle foreach
La plupart des développeurs ne connaissent pas le comportement qui va suivre et je suis très bien placé pour le dire car je l’ai déjà vérifié lors d’interviews de développeurs (rassurez-vous, cette question n’avait aucune incidence sur le test).
Avec C# 4.0 (voire C# 2.0 et 3.0 si nous remplaçons l’utilisation de lambda par des délégués), quel résultat affichera ce code ?
static void Main(string[] args)
{
var values = new List<int>() { 1, 2, 3, 4, 5 };
var funcs = new List<Func<int>>();
foreach (var v in values)
{
funcs.Add(() => v * 10);
}
foreach (var f in funcs)
{
Console.WriteLine(f());
}
}Si vous pensiez à « 10 20 30 40 50 », c’est raté. La bonne réponse est en fait « 50 50 50 50 50 ».
La raison de ce comportement est que la variable v est déclarée en dehors de la boucle. Cette même variable est ensuite utilisée à chaque itération. Du coup, lorsque la boucle est terminée, les expressions lambda précédemment créées utilisent chacune la même variable dont la valeur est donc 5.
Avec C# 5.0, ce comportement a été changé afin que la variable v soit déclarée à l’intérieur de la boucle pour chaque itération. Ainsi, chaque expression lambda va capturer la variable v qui ne changera pas de valeur à l’itération suivante. Le résultat est donc à présent « 10 20 30 40 50 ». Vous aviez raison tout compte fait !
Évidemment ce changement n’est pas sans conséquence et si vous avez écrit du code dans le passé exploitant ce comportement, vous aurez des problèmes lorsque vous porterez votre code sous C# 5.0.
Conclusion
Comme vous avez pu le constater, l’équipe Visual C# de Microsoft ne cesse de nous proposer de belles surprises à chaque nouvelle version du langage.
Grâce à l’utilisation de async et await, vous allez pouvoir développer du code asynchrone sans trop vous poser de question. Vous gagnerez du temps en termes de développement et vous rendrez plus lisible votre code. Du côté des attributs Caller Information, vous pourrez bâtir des solutions de diagnostiques et de trace encore plus complètes.
Encore une fois, cette nouvelle version de C# vous permettra de faire beaucoup plus avec beaucoup moins.
Remerciements
Je tiens à remercier Nathanael Marchand et tomlev pour leur relecture technique, ainsi que f-leb pour la correction orthographique.